Webb Kimmel

Data Analyst looking for opportunities
Unique background in business, outdoor recreation and customer service
Outdoor enthusiast, raft guide, reader
View My LinkedIn Profile
Analyzing HR Data with R

Human Resources are the most valuable resources for any business. It is important to find ways to attract employees that fit are a good fit for the company and role they are performing, and to create an environment that keeps those employees motivated and content at the company. In this data analysis I used R, a powerful statistical analysis language, to gain insights from an IBM HR dataset to try to determine why employee attrition at IBM was increasing.
The IBM Dataset
For this project I am taking on the role of an IBM People Data Analyst intern. Recently there have been many employees leaving the company and IBM leadership wants to know why. This dataset was created by IBM data scientists but is a fictional dataset. The data contains 1,470 rows each representing an employee, and there are 35 columns tracking different attributes that describe these employees. Here is the original dataset. The “Attrition” column will be the most important attribute for this project as this tells us whether the employee stayed at IBM. There are columns that contain demographic data such as age, education, and marital status. Other columns contain job-related data like monthly income, years at the company, and categorical numbers for things like performance rating and work-life balance. I was asked to determine the following:
- Are there any significant correlations between the most important attributes?
- What trends can exist between these correlated attributes?
- Is there any evidence of ageism in attrition rates?
- How much do factors like age, monthly income, work-life balance, and distance from home affect the chances of an employee leaving the company?
Using R I will try to gain valuable insights from this data.
Statistical Analysis with R
Determining Data Relationships
First, I want to find out if there are any correlations between the most important attributes in this dataset. IBM determined that age, daily rate, distance from home, education, hourly rate, monthly income, monthly rate, number of companies worked at, total working years, and training times last year are significant variables they want to track. Before I determine relationships between these attributes, I need to read the data into RStudio to create a data frame.
Read Data into R
Now that I have the data frame created, I can run the correlation matrix for the important attributes using the “cor” function in R. See the results below:
Correlation Matrix
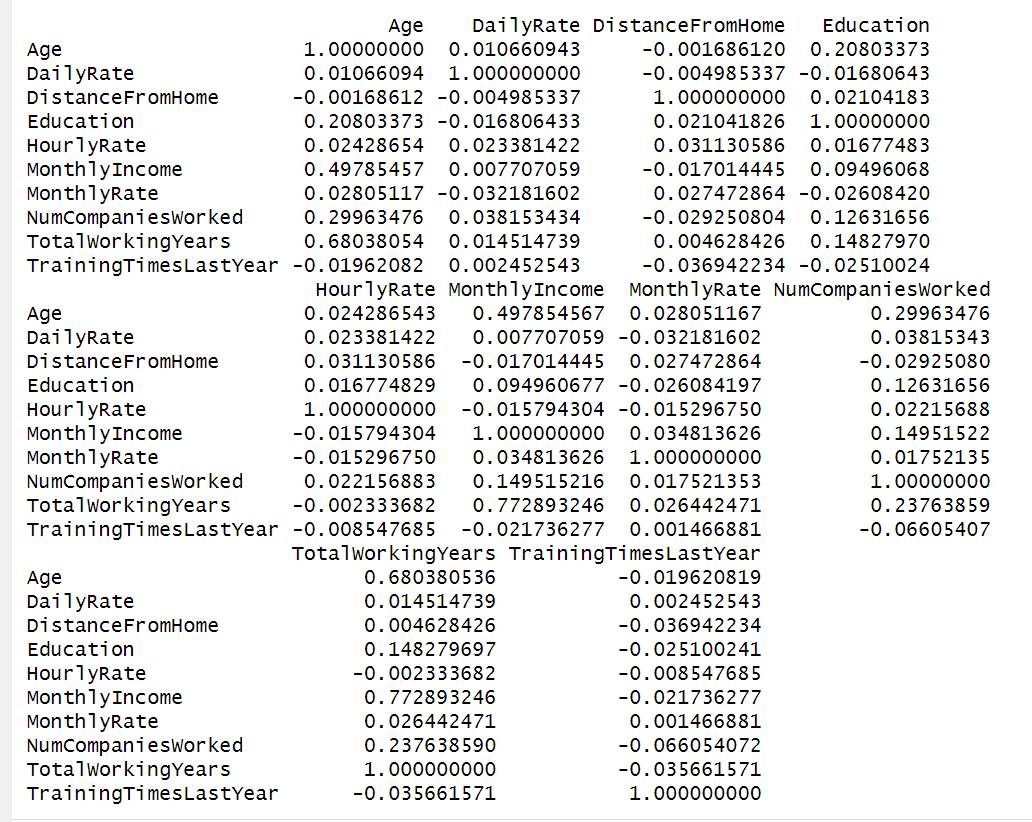
Based on these results I determined that there were significant relationships between Age and Monthly Income, Total Working Years, and Education. To learn more about these relationships I wanted to see the data. A fantastic way to get a quick picture of these relationships is to create a pair plot in R.
Pairplot Visualizations


I can see a few things that stand out in this data visualization. Interestingly, education level does not appear to have a substantial impact on monthly income, and age is not as big a factor in education as one might expect. Education in this dataset is a categorical numerical value with “1” meaning below college level education, and “5” meaning doctorate level. In these plots I can see multiple employees with doctorate-level education making less than $5,000 per month. I can also see examples of employees in their late twenties and early thirties with doctorates.
There does appear to be a clear threshold when comparing monthly income with total working years. This plot shows a distinct line where employees with over twenty total working years are making at least $5,000 per month.
Finally, I see that age does have a positive correlation with monthly income, but again, this is not as pronounced as I expected. While there are no employees under twenty making more than $5,000 per month, employees aged twenty-five and above have monthly incomes covering the full range of values. This is an interesting group of employees!
Bias in Firing Decisions?
A disgruntled employee has decided to sue IBM after being laid-off. They claim that the company’s layoffs were influenced by ageism, saying that older employees were laid-off at a higher rate than younger ones. Leadership would like to dispel these claims and needs the data to prove it. To do this I will do some hypothesis testing. I first wanted to create a box plot comparing Age and Attrition to see the data, and any clear bias that may exist.
Age vs. Attrition Boxplot
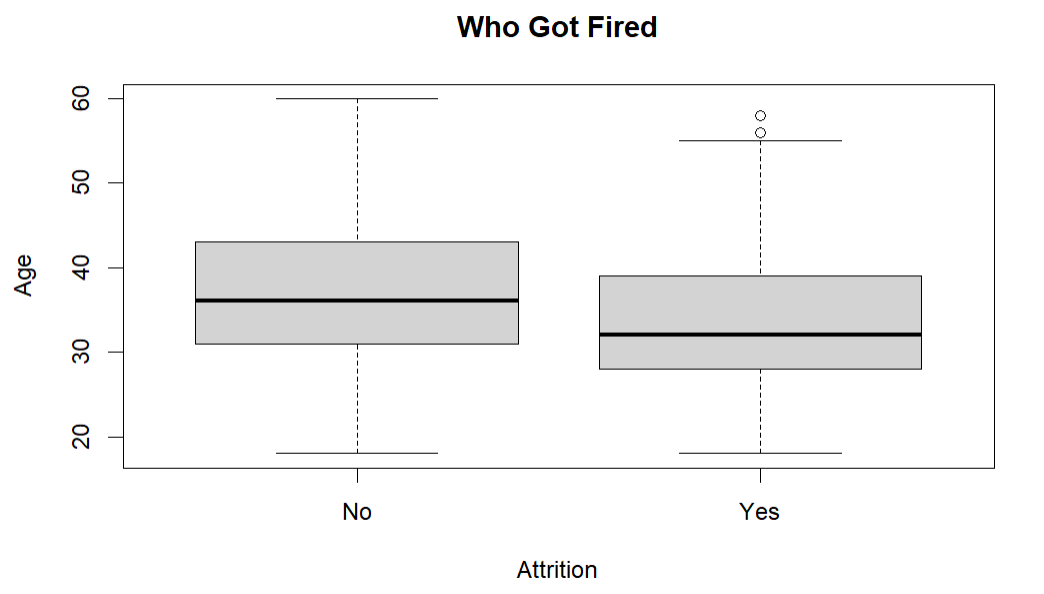
These boxplots look fairly similar. However, the thick black line in these plots shows the median age for the “Yes” and “No” categories from the Attrition column. The median age for the “Yes” column is clearly lower than the median age of the “No” category, meaning the average age of employees that were let go is likely lower than the average of employees retained. I can further show this by performing a Welch two sample t-test to get a more statistical comparison of the two groups. To perform the t-test I first have to create two new variables, one to represent employees that stayed (“No” values) and one to represent employees that left (“Yes” values). Once I declare these two arrays I can run the t-test.
Welch Two Sample T-Test


Looking at these results I can further disprove the claim that ageism was present in layoff decisions. Here the p-value is especially important. A p-value of 0.05 or below means that age is a statistically significant factor compared to attrition. Our p-value is much lower, showing that there is a statistically significant relationship between these two attributes, but not in the way the disgruntled employee claimed. In the results the x variable represents employees that left, and the y variable is employees that stayed. Looking at the confidence intervals I can be 95% confident that the “Yes” group is smaller than the “No” group. Furthermore, the mean values for x and y show that the average age of employees that left the company is lower than the average of those who stayed, 34 and 38, respectively. IBM can say, with confidence, that layoffs were not made with an ageism bias.
Regression Modeling with R
One of the most powerful uses of R is to create statistical models. A common example of this is linear regression. With linear regression I can predict a target value by simply knowing certain input variables. Here is a simple linear regression I created to predict monthly income based on age.
Monthly Income Regression Model


| There are a few key values to examine in the results of this linear regression. The first is the Coefficient Pr(> | t | ). This shows the p-values calculated using the probability distribution (t-distribution) created by the regression model. Age has a p-value well below the 0.05 threshold for statistical significance, so I can be confident that age is a significant factor for predicting monthly income. The “Signif. codes” legend is just a quick representation of the significance of our input variable. Because the p-value is basically zero, the age input gets “***”, meaning it is very statistically significant. Finally, the R-squared value shows how much of the variance in monthly income can be explained by the input variable (age). In this model the R-squared shows us that about 25% of the variance in monthly income is explained by changes in age. Pretty cool! |
For this project I am more concerned with predicting attrition. Linear regressions are great for predicting values when comparing continuous data points. The “Attrition” column only has two values though, meaning this data is a binary categorical value. Linear regressions are not great for predicting binary values. Doing some more research, I determined that I need to use a Logistic Regression, also known as a logit model. However, R cannot interpret string values for the purposes of a logit model, so I first need to convert the “Yes” and “No” values in the attrition column to 1’s and 0’s.
Converting the Attrition Column to Binary Numbers

Now that I have converted those values into a readable format for the logit model, I can create models to see how factors like age, monthly income, work-life balance, and distance from home affect the chances of an employee leaving the company. Here are a few models I created using logistic regression.
Predicting Attrition based on Age


Predicting Attrition based on Monthly Income


Predicting Attrition based on Work-Life Balance

Predicting Attrition based on Distance from Home


Based on these models we can see if any of these factors are statistically significant for predicting employee attrition. In the first model I can see that Age again has a p-value well below 0.05, so it is significant. Next, we have the logistic regression coefficients. These show the odds of attrition for a one unit increase in the input variable, in this case age. With a coefficient value of -0.05 I can say that for every additional year of age the likelihood of employee attrition decreases by 5%. This aligns with the hypothesis testing I performed earlier in this project.
Looking at the other models I can assess how the attrition probability changes for the other factors I am interested in. Monthly Income is statistically significant, but the effect on the odds of attrition is miniscule. Work-Life Balance is also a categorical variable with a “1” being bad work-life balance and a “5” being the best work-life balance. I can see that work-life balance is statistically significant, and that an increase in balance corresponds to a 24% reduction in the odds of attrition. This means that if IBM wishes to reduce attrition rates, they may want to consider improving the work-life balance of their employees. Distance from home is also a significant factor but does not affect the odds of attrition very much.
Key Takeaways
These are the insights I was able to discover through my data analysis with R:
- There were significant correlations between age, monthly income, education, and total working years.
- There were some clear positive trends between age and monthly income, and total working years and monthly income, but trends between age and education, and education and total monthly income were less clear than I expected.
- The data proved that there was no ageism bias in relation to lay-off decisions.
- The most significant predictor of employee attrition is work-life balance which could change how IBM manages their employees’ time.
Thank you so much for reading this project write-up for my statistical analysis of IBM data using R! This was a great project to increase my analytical skills and for learning more about statistical analysis and HR management. If you enjoyed this analysis, or have any questions or feedback please comment on this project to let me know! If you would like to follow along for more data analysis projects feel free to connect with me on LinkedIn. This was another fun project I completed as part of the Data Career Jumpstart curriculum.